Getting started
Dagster orchestrates dbt alongside other technologies, so you can schedule dbt with Spark, Python, etc. in a single data pipeline. Dagster's asset-oriented approach allows Dagster to understand dbt at the level of individual dbt models.
Prerequisites
To follow the steps in this guide, you'll need:
-
A basic understanding of dbt, DuckDB, and Dagster concepts such as assets and resources
-
To install the dbt and DuckDB CLIs
-
To install the following packages:
pip install dagster duckdb plotly pandas dagster-dbt dbt-duckdb
Setting up a basic dbt project
Start by downloading this basic dbt project, which includes a few models and a DuckDB backend:
git clone https://github.com/dagster-io/basic-dbt-project
The project structure should look like this:
├── README.md
├── dbt_project.yml
├── profiles.yml
├── models
│ └── example
│ ├── my_first_dbt_model.sql
│ ├── my_second_dbt_model.sql
│ └── schema.yml
First, you need to point Dagster at the dbt project and ensure Dagster has what it needs to build an asset graph. Create a definitions.py in the same directory as the dbt project:
import dagster as dg
from dagster_dbt import dbt_assets, DbtCliResource, DbtProject
from pathlib import Path
# Points to the dbt project path
dbt_project_directory = Path(__file__).absolute().parent / "basic-dbt-project"
dbt_project = DbtProject(project_dir=dbt_project_directory)
# References the dbt project object
dbt_resource = DbtCliResource(project_dir=dbt_project)
# Compiles the dbt project & allow Dagster to build an asset graph
dbt_project.prepare_if_dev()
# Yields Dagster events streamed from the dbt CLI
@dbt_assets(manifest=dbt_project.manifest_path)
def dbt_models(context: dg.AssetExecutionContext, dbt: DbtCliResource):
yield from dbt.cli(["build"], context=context).stream()
# Dagster object that contains the dbt assets and resource
defs = dg.Definitions(assets=[dbt_models], resources={"dbt": dbt_resource})
Adding upstream dependencies
Oftentimes, you'll want Dagster to generate data that will be used by downstream dbt models. To do this, add an upstream asset that the dbt project will as a source:
import dagster as dg
from dagster_dbt import dbt_assets, DbtCliResource, DbtProject
from pathlib import Path
import pandas as pd
import duckdb
import os
duckdb_database_path = "basic-dbt-project/dev.duckdb"
@dg.asset(compute_kind="python")
def raw_customers(context: dg.AssetExecutionContext) -> None:
# Pull customer data from a CSV
data = pd.read_csv("https://docs.dagster.io/assets/customers.csv")
connection = duckdb.connect(os.fspath(duckdb_database_path))
# Create a schema named raw
connection.execute("create schema if not exists raw")
# Create/replace table named raw_customers
connection.execute(
"create or replace table raw.raw_customers as select * from data"
)
# Log some metadata about the new table. It will show up in the UI.
context.add_output_metadata({"num_rows": data.shape[0]})
dbt_project_directory = Path(__file__).absolute().parent / "basic-dbt-project"
dbt_project = DbtProject(project_dir=dbt_project_directory)
dbt_resource = DbtCliResource(project_dir=dbt_project)
dbt_project.prepare_if_dev()
@dbt_assets(manifest=dbt_project.manifest_path)
def dbt_models(context: dg.AssetExecutionContext, dbt: DbtCliResource):
yield from dbt.cli(["build"], context=context).stream()
# Add Dagster definitions to Definitions object
defs = dg.Definitions(
assets=[raw_customers, dbt_models],
resources={"dbt": dbt_resource},
)
Next, you'll add a dbt model that will source the raw_customers asset and define the dependency for Dagster. Create the dbt model:
select
id as customer_id,
first_name,
last_name
from {{ source('raw', 'raw_customers') }} # Define the raw_customers asset as a source
Next, create a _source.yml file that points dbt to the upstream raw_customers asset:
version: 2
sources:
- name: raw
tables:
- name: raw_customers
meta: # This metadata:
dagster: # Tells dbt where this model's source data is, and
asset_key: ["raw_customers"] # Tells Dagster which asset represents the source data
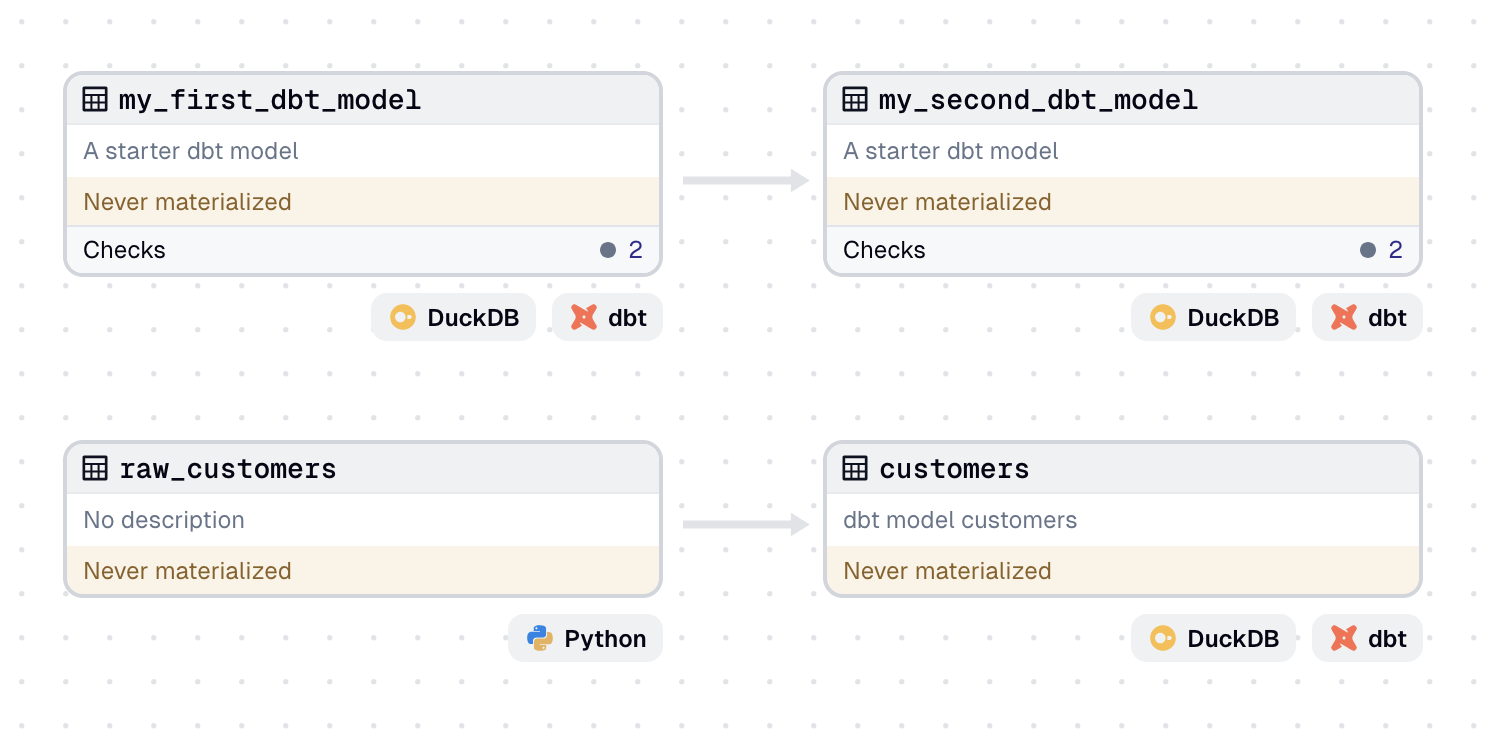
Adding downstream dependencies
You may also have assets that depend on the output of dbt models. Next, create an asset that depends on the result of the new customers model. This asset will create a histogram of the first names of the customers:
import dagster as dg
from dagster_dbt import dbt_assets, DbtCliResource, DbtProject, get_asset_key_for_model
import plotly.express as px
from pathlib import Path
import pandas as pd
import duckdb
import os
duckdb_database_path = "basic-dbt-project/dev.duckdb"
@dg.asset(compute_kind="python")
def raw_customers(context: dg.AssetExecutionContext) -> None:
# Pull customer data from a CSV
data = pd.read_csv("https://docs.dagster.io/assets/customers.csv")
connection = duckdb.connect(os.fspath(duckdb_database_path))
# Create a schema named raw
connection.execute("create schema if not exists raw")
# Create/replace table named raw_customers
connection.execute(
"create or replace table raw.raw_customers as select * from data"
)
# Log some metadata about the new table. It will show up in the UI.
context.add_output_metadata({"num_rows": data.shape[0]})
dbt_project_directory = Path(__file__).absolute().parent / "basic-dbt-project"
dbt_project = DbtProject(project_dir=dbt_project_directory)
dbt_resource = DbtCliResource(project_dir=dbt_project)
dbt_project.prepare_if_dev()
@dbt_assets(manifest=dbt_project.manifest_path)
def dbt_models(context: dg.AssetExecutionContext, dbt: DbtCliResource):
yield from dbt.cli(["build"], context=context).stream()
@dg.asset(
compute_kind="python",
# Defines the dependency on the customers model,
# which is represented as an asset in Dagster
deps=[get_asset_key_for_model([dbt_models], "customers")],
)
def customer_histogram(context: dg.AssetExecutionContext):
# Read the contents of the customers table into a Pandas DataFrame
connection = duckdb.connect(os.fspath(duckdb_database_path))
customers = connection.sql("select * from customers").df()
# Create a customer histogram and write it out to an HTML file
fig = px.histogram(customers, x="FIRST_NAME")
fig.update_layout(bargap=0.2)
fig.update_xaxes(categoryorder="total ascending")
save_chart_path = Path(duckdb_database_path).parent.joinpath(
"order_count_chart.html"
)
fig.write_html(save_chart_path, auto_open=True)
# Tell Dagster about the location of the HTML file,
# so it's easy to access from the Dagster UI
context.add_output_metadata(
{"plot_url": dg.MetadataValue.url("file://" + os.fspath(save_chart_path))}
)
# Add Dagster definitions to Definitions object
defs = dg.Definitions(
assets=[raw_customers, dbt_models, customer_histogram],
resources={"dbt": dbt_resource},
)
Scheduling dbt models
You can schedule your dbt models by using the dagster-dbt's build_schedule_from_dbt_selection function:
import dagster as dg
from dagster_dbt import (
dbt_assets,
DbtCliResource,
DbtProject,
get_asset_key_for_model,
build_schedule_from_dbt_selection,
)
from pathlib import Path
import plotly.express as px
from pathlib import Path
import pandas as pd
import duckdb
import os
duckdb_database_path = "basic-dbt-project/dev.duckdb"
@dg.asset(compute_kind="python")
def raw_customers(context: dg.AssetExecutionContext) -> None:
# Pull customer data from a CSV
data = pd.read_csv("https://docs.dagster.io/assets/customers.csv")
connection = duckdb.connect(os.fspath(duckdb_database_path))
# Create a schema named raw
connection.execute("create schema if not exists raw")
# Create/replace table named raw_customers
connection.execute(
"create or replace table raw.raw_customers as select * from data"
)
# Log some metadata about the new table. It will show up in the UI.
context.add_output_metadata({"num_rows": data.shape[0]})
dbt_project_directory = Path(__file__).absolute().parent / "basic-dbt-project"
dbt_project = DbtProject(project_dir=dbt_project_directory)
dbt_resource = DbtCliResource(project_dir=dbt_project)
dbt_project.prepare_if_dev()
@dbt_assets(manifest=dbt_project.manifest_path)
def dbt_models(context: dg.AssetExecutionContext, dbt: DbtCliResource):
yield from dbt.cli(["build"], context=context).stream()
@dg.asset(
compute_kind="python",
# Defines the dependency on the customers model,
# which is represented as an asset in Dagster
deps=[get_asset_key_for_model([dbt_models], "customers")],
)
def customer_histogram(context: dg.AssetExecutionContext):
# Read the contents of the customers table into a Pandas DataFrame
connection = duckdb.connect(os.fspath(duckdb_database_path))
customers = connection.sql("select * from customers").df()
# Create a customer histogram and write it out to an HTML file
fig = px.histogram(customers, x="FIRST_NAME")
fig.update_layout(bargap=0.2)
fig.update_xaxes(categoryorder="total ascending")
save_chart_path = Path(duckdb_database_path).parent.joinpath(
"order_count_chart.html"
)
fig.write_html(save_chart_path, auto_open=True)
# Tell Dagster about the location of the HTML file,
# so it's easy to access from the Dagster UI
context.add_output_metadata(
{"plot_url": dg.MetadataValue.url("file://" + os.fspath(save_chart_path))}
)
# Build a schedule for the job that materializes a selection of dbt assets
dbt_schedule = build_schedule_from_dbt_selection(
[dbt_models],
job_name="materialize_dbt_models",
cron_schedule="0 0 * * *",
dbt_select="fqn:*",
)
# Add Dagster definitions to Definitions object
defs = dg.Definitions(
assets=[raw_customers, dbt_models, customer_histogram],
resources={"dbt": dbt_resource},
schedules=[dbt_schedule],
)